The Stocks Report: The Journey of a Side Project
The Stocks Report: The Journey of a Side Project
This is a story on the journey I took while building stocks, my favourite and best maintained Breakable Toy (as I later learned these projects are called, see my review on the mentioning book),
In April 2016 I decided to build a database to help me manage my food stocks at home. The main features I had in mind were to
inform me about expiration dates so I don't waste food by forgetting about it in the back of the cupboard.
help me to decide what to buy while standing in the supermarket.
support several devices, imagining some flat mates sharing their fridge.
check all the above information without internet connectivity.
At the time of deciding whether this was worth a side project I had taken some classes on DB design and had a basic understanding of programming in Java and some other languages. So whatever I was going to build would be rather hobbyist and barely serve my own needs. While this was certainly true for the first versions, the current state of the system is quite mature. Convince yourself.
Researching what tools are available for this job I got my hands on some code from colleagues who implemented a similar data management problem (which I later learned to be known as CRUD) in Java. Since I wanted to get something done quickly, I copied large parts of it and so chose my tech-stack to consist of:
MariaDB for the SQL database. I first had to check if doing web requests which in turn ask a database for the response are actually fast enough for this purpose. Only then I learned that this is how almost all web applications work.
Java Servlets with Jersey to provide a JSON REST API consumed by several clients.
Jetty as the servlet container
As already mentioned, for me as an unexperienced Java developer, I didn't spend too much time on evaluating different options (leading to both Jetty and MariaDB being no longer used in stocks today ;) ).
I was really worried about security. I planned to expose a self-written application running in my local network to the entire Internet while not having any experience in doing this. So I wanted to have only authorised network traffic to arrive at my application and all communication should be encrypted. This lead me to TLS. Hard to imagine nowadays but there was no Let's Encrypt when I started this. A TLS certificate by some CA was also no solution to the "only authorised network traffic" requirement as it only authenticates the server but not the client. So I made stocks manage its own CA and all clients would have to use client certificates to use the API. To get a client certificate the new client has to receive a off-band secret from an already registered device and present it to the server. All TLS is managed by nginx, so I don't have to deal with TLS in my application. To support device removal the CA also enforces its own CRL which is refreshed whenever a device is removed.
Baby System is Up and Running
Some months later I had a servlet and a CLI client to manage food types, food items, the locations where they are stored and their respective expiration dates, see the fancy ER diagram from that time. This was the time when I took the laptop into the kitchen to enter all the data on my currently present food into the database. It was not user-friendly. The shell didn't even have working arrow keys for cursor moving or history scrolling. Even more problematic, as I continued coding I often introduced bugs rendering the whole system unusable which hurt me days later when I wanted to register the latest food I bought. There were still a lot of problems to solve.
{kind=link}
On the technical side I had by now learned about
Building java projects with maven
Archlinux packaging
configuring TLS and operating a CA
interacting with a database from inside a program with JDBC (yes I handcrafted all the SQL and still think this is a good idea)
But looking at my requirements I had barely reached the goal of managing expiring food (my CLI kind of knew about it) but it wasn't easily usable and I definitely wouldn't take the laptop to the grocery store to check my stocks from there. All I had was the burden of registering food data after each grocery shopping.
Data Synchronization
The client has all data in the system available in its own local database (with sqlite) to support offline usage to read the data. All data modifications are sent to the server which maintains an Updates table and stores for each DB table when the last change occurred to it. To synchronise the client fetches the Updates table and subsequently all other tables which have a more recent timestamp than the local one.
Android
Writing an android app has been on my wish list since at least 2012 but I had no idea on what to code. Stocks finally gave me this idea. Another two months passed after I arrived at the first usable app. All of my pride at that time was the feature that the app was aware of background data changes to its own database and could live-update the UI once a change was downloaded to the client.
Now I had an android app on my mobile to check stocks while standing inside the supermarket, and I could see a sorted list of expiring food items, so I was done? It turns out I was not as I had a ton of ideas for further changes. To keep track of all these ideas I recorded them in text files, which now look like the most archaic implementation of an issue tracker, see e.g. here for a taste. Github already had an issue tracker but I was worried about vendor lock-in. At the same time I started a job as developer and learned about JIRA and definitely wanted something more fancy than these text files (while I still think that an issue tracker weaved into the repository itself might be an interesting side project). So I started hosting JetBrains Youtrack, which is also a form of vendor lock-in but at least it runs on my own machines...
Tomcat and Rigorous Testing
Also during my first job I learned about the concept of Continuous Integration (I already had Travis CI at that time but it only compiled the code) and running somem code tests after each change to the system to have confidence that everything still works and is ready to be released. This was precisely what I needed. Unfortunately I had no tests and no motivation to change this. So I deferred this to later.
For reasons I cannot fully reconstruct any more (but it had something to do with missing logging features) I decided to migrate from Jetty to Tomcat as the servlet container. This was a big change and I was concerned about breaking my CA handling and introduce security problems. This lead me back to the missing testing infrastructure. So I used the tools I knew at that time and built a test script to execute end-to-end tests on my REST API (yes, these tools were curl and grep, what's the point? See here, the code is not that bad). I also learned about ansible to automatically set up a stocks instance to run the tests on. I also learned about code coverage and decided to push testing to the limits as I was really frustrated by all the small bugs which always popped up when I stood in front of a heap of food to be registered. So testing after all was a self-defence I took to reduce my stress on this problem. The tests didn't only cover the code but also the DB interaction and overall servlet integration. Both were a big risk as SQL syntax errors contained in the Java code could break features and wrong configuration of the servlet could prevent it from starting up at all. I took the pragmatic approach of mixing unit- and integration tests with the database as there was almost no pure business logic to test without DB and the performance overhead was really negligible.
Later I eventually heared of Rest Assured, a Java library for REST API testing which replaced the giant bash script, but this only happened as late as July 2018.
To improve testability I introduced the Spring Core Framework for both the CLI client as well as the server as its dependency injection greatly helped in writing testable code and inject dummies, mocks and spies into the code.
All this testing took a LOT of time, roughly 10 months. But in July 2017 I was done and had a server and client which where covered by all unit, integration (with DB) and system tests. Client and server were deployed on separate VMs and a python test driver even entered real text commands into the CLI client and verified the textual results. Was it worth it? Definitely. I found bugs from Archlinux system upgrades, e.g. a change in the nginx HTTP header format for the client certificate's CN which broke my parser for this. After this incident I ran the tests before each productive system upgrade. There was also a timezone bug which only showed while UTC and local time differed in the date which is one hour in darkest night in CET where I usually reside. I found this bug by running the test suites for 24 hours as fast as possible (one run took about 10 minutes and back then I had no problems with flaky tests...). I really gained confidence into my tests and learned to appreciate them. From now on no feature should be implemented without accompanying tests.
But you might have noticed what I didn't mention so far: There were no tests on android so far. This only changed in September 2017 when I took the deep dive into Espresso, the android tool for automated UI tests. All I want to say about it that some days later I had UI tests for the most important use cases, they found some bugs (so payed off) and since then my test suite was flaky. I did keep them anyway because running them is cheap enough to run them until they are green. Up until today stocks has no unit or integration tests for the android client. I never had the motivation to learn how to get rid of and mock the omnipresent Context object every Android API part appears to need.
EAN codes and DB migrations
Checking in each food item on its own is really cumbersome. As everybody knows, each food item has a barcode which can be read by machines to identify them, called EAN codes. I wanted to support them in stocks. So the database had to store a mapping from EAN codes to food types and the android client should be able to read them and look them up in the database. This required a SQL migration which for years I would be doing by simply packaging an (untested!!) SQL script and adapt the schema for new installations to contain the changed models. For a long time this, and a note in the upgrade instructions, were all I gave to upgrade database schemas.
Circuit Breakers, Error Codes and Data Versions
After reading "Release It" 1 I wanted to have circuit breakers in my application. It helps in situations of high load when distributed systems tend to become unresponsive and each system only blocks on another system to reply with data it needs. This leads to overall no progress in the system. A circuit breaker is a device between two systems measuring how long it takes for the communication to complete. If it takes too long or gives an error, the circuit breaker trips and any following requests won't reach the other system to give it some time to recover. The circuit is now open. Only after some time the circuit breaker closes again. The Hystrix library is such a system and I subsequently integrated it into stocks. However it can be really annoying as on small systems, random load on other programs can cause stocks to slow down and trip the circuit breaker without being a "real" problem. Especially during system boot up CPU is a scarce resource and the stocks is likely to trip in that case. So I am not completely convinced by now that this feature was a good idea.
There were also several changes to the REST protocol I wanted to make. If a circuit breaker trips or some other error occurs, the client should be notified instead of just being given an empty result. So error codes had to be introduced. This required a change to the structure of the JSON responses the server gives.
Also while stocks relied on the transactional properties of the database there were situations of concurrent data modification which were unpleasant for users. E.g. user A edits the name of a food type to value A and user B edits the same food type's name to value B. If there are minutes between these changes (and since stocks encourages local copies of the database user B might not refresh his local data before the update to value B) the second change will overwrite the first one and no transactional system will protect from this. To tell the server that the client operates on the latest data the solution was row-based versioning: Each database row carries a version which is monotonically incremented on each data change. Updates may only happen if the update request passes the latest version number and is rejected otherwise. This way user B cannot update the name to value B as he would send an outdated version for the data record.
As part of this large change I also got rid of the manual SQL code and replaced it with JOOQ which is a fluent API to generate SQL for a fixed data models. This relaxed the problem of writing illegal SQL but I already had this covered by the tests, so it was rather a question of coding comfort.
The server changes for the new protocol were done in October 2018 but the android client (which was the later of the two clients) was only done in May 2019 when it was also migrated to Android Jetpack, but this is a rather boring story.
PostgreSQL and serialisability
In December 2018 I also decided to move to PostgreSQL and run all SQL transactions on the strictest (and slowest) isolation level, SERIALIZABLE. For data consistency this is the most desirable level and as performance didn't degrade perceivably I decided to go for it.
On this level it is important to know that transactions may fail as a concurrent DB transaction may obsolete all changes done so far. Stocks now tries to run the transaction repeatedly until no more serialisation problem occurs. This behaviour terminates because after an abort due to a concurrent modification the next try will either succeed, be again aborted by another concurrent transaction (which is only triggered by users and will eventually no longer occur) or will result in an error due to mismatched data versions.
Shopping List Support
Amazingly only in August 2019 I completed a very cool feature, shopping lists. The entire stocks instance has a shared shopping list of food types which should be bought next. Up to now I really managed these little paper notes to record what to buy. Ancient technology, I know. Most important: If an item of a certain food type is registered, the food is automatically removed from the shopping list. As apparent as it is, this was a really great improvement for me.
Even More Improvements
Since February 2020 stocks uses C3P0 connection pool. This was a considerable performance improvement on my productive instance as my DBMS not only requires a TCP handshake on connection but also a TLS handshake (for security, you know).
Also since then all endpoints which return large data sets stream their response instead of first loading the result completely into RAM and only then forwarding it to the client. A disadvantage of my JSON serialiser is that the streaming part happens completely outside of stocks's control. So after the streaming is done there is no way for stocks to close the DB connection and I have to put this burden on C3P0 to close connections not returned after a fixed amount of time.
Only since August 2020 stocks is able to automatically migrate its database via the liquibase library.
Bitemporal Data
In August 2020 I wanted to have an activity feed of all data changes that happened on the database. This was again a huge change and I reported about this already here.
What I haven't described there is that stocks can now show nice plots. In the screenshot (which is in German unfortunately) the first plot shows the number of peppers over time and the lower histgram shows how many days before expiry most peppers are consumed. Line and bar chart of food type peppers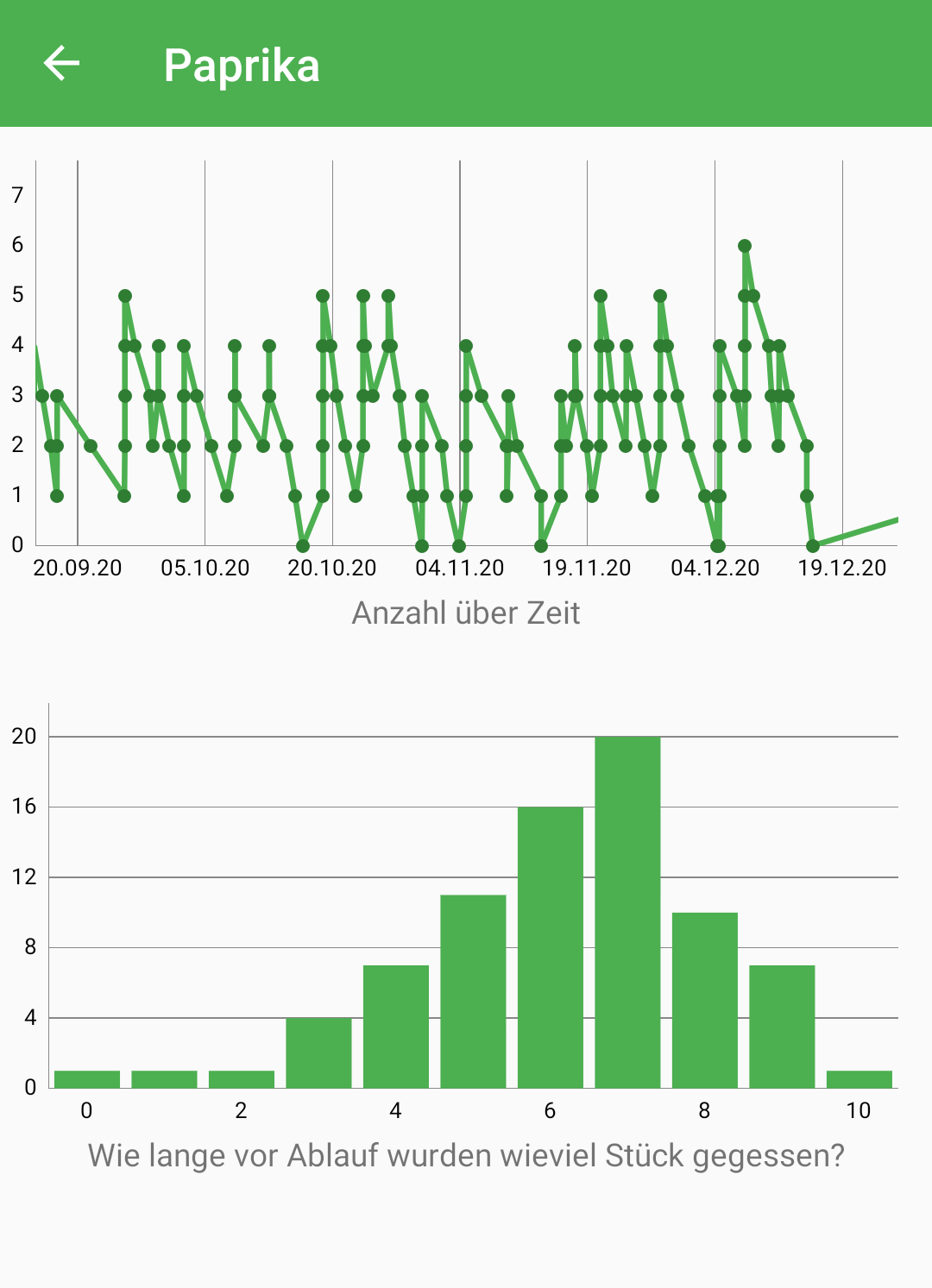
Summary
These are the most important milestones stocks took from its first baby steps and a laptop in the kitchen to a usable management tool. As of now I don't know for sure how many people except me are using this system (attempts to enlighten family members for own stocks instances have failed so far and a friend of mine has given it a try). I have been using this system for 4.5 years and don't want to miss it any more. I use it at least 4 times a day.
But besides having a usable stocks management system the greatest benefit of this project was the experience I gained while programming it and getting in touch with all the different problems and their solutions. It is a completely different problem to maintain and evolve a system over several years than it is to just code something up and dump it once the university course is over (which was until then the only way of software development I knew).
I am still a little sad that in all those years I never found any colleague to collaborate with on this, despite several advertisements and opportunities which then fizzled out again and Mr. Stallman who claimed the best way to find collaborators is to put all the code under GNU GPL3. But maybe this report will find its way to an encouraged fellow coder and users.
Michael T. Nygard: Release It!: Design and Deploy Production-Ready Software (Pragmatic Programmers). Published April 6th 2007 by Pragmatic Bookshelf.